CogVideo
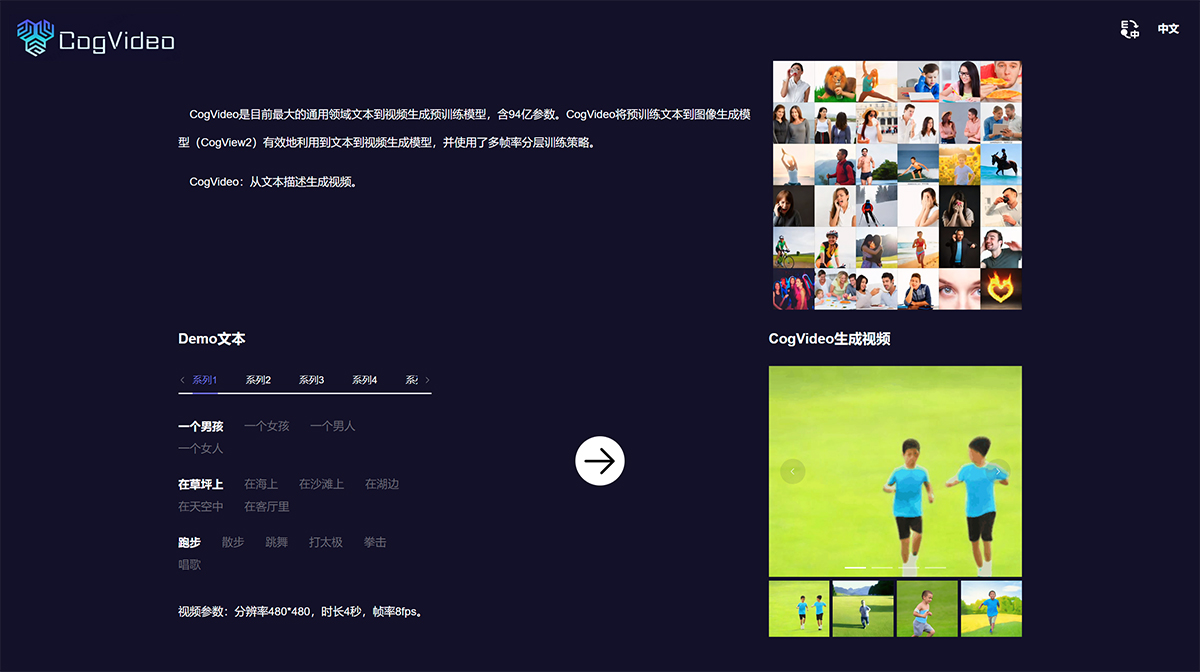
CogVideo是目前最大的通用领域文本到视频生成预训练模型,含94亿参数。CogVideo将预训练文本到图像生成模型(CogView2)有效地利用到文本到视频生成模型,并使用了多帧率分层训练策略。
")
CogVideo由清华大学和BAai唐杰团队提出的开源预训练文本到视频生成模型,它在GitHub上引起了广泛关注。该模型的核心技术基于深度学习算法和模型架构,能够将文本描述转换为生动逼真的视频内容。
CogVideo采用了多帧率分层训练策略,通过继承预训练的文本-图像生成模型CogView,实现了从文本到视频的高效转换。此外,CogVideo还具备先进的动态场景构建功能,能够根据用户提供的详细文本描述生成3D环境及动画,同时,CogVideo还能高效地微调了文本生成图像的预训练用于文本生成视频,避免了从头开始昂贵的完全预训练。
CogVideo的训练主要基于多帧分层生成框架,首先根据CogView2通过输入文本生成几帧图像,然后通过插帧提高帧率完成整体视频序列的生成。这种训练策略赋予了CogVideo控制生成过程中变化强度的能力,有助于更好地对齐文本和视频语义。该模型使用了94亿个参数,是目前最大的通用领域文本到视频生成预训练模型之一。
CogVideo不仅支持中文输入,还提供了详细的文档和教程,方便研究者和开发者使用和定制。它的开源和易于使用特性,使其在多模态视频理解领域具有重要的应用价值。此外,CogVideo的出现标志着AI技术在视频生成领域的重大进步,为未来的创作提供了颠覆性的想象空间。
总的来说,CogVideo作为一款强大的文本生成视频模型,能够有效地利用预训练模型,生成高质量的视频。但在生成视频的过程中也面临着一些挑战,比如文本-视频数据集的稀缺性和弱相关性阻碍了模型对复杂运动语义的理解,这都需要进一步的研究和改进。
数据评估
AI工具箱提供的CogVideo都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由AI工具箱实际控制,在2024年10月6日 上午4:49收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,AI工具箱不承担任何责任。
相关导航