ChatTTS-Forge是一个围绕 TTS生成模型开发的项目,为用户提供灵活的TTS生成能力,支持多种音色、风格控制、长文本推理等功能,ChatTTS-Forge提供了各种API(应用程序编程接口),开发人员可以直接使用这些API轻松将文本转换为语音。
ChatTTS-Forge 是一个围绕 TTS(文本转语音)生成模型开发的项目。为用户提供灵活的TTS生成能力,支持多种音色、风格控制、长文本推理等功能。
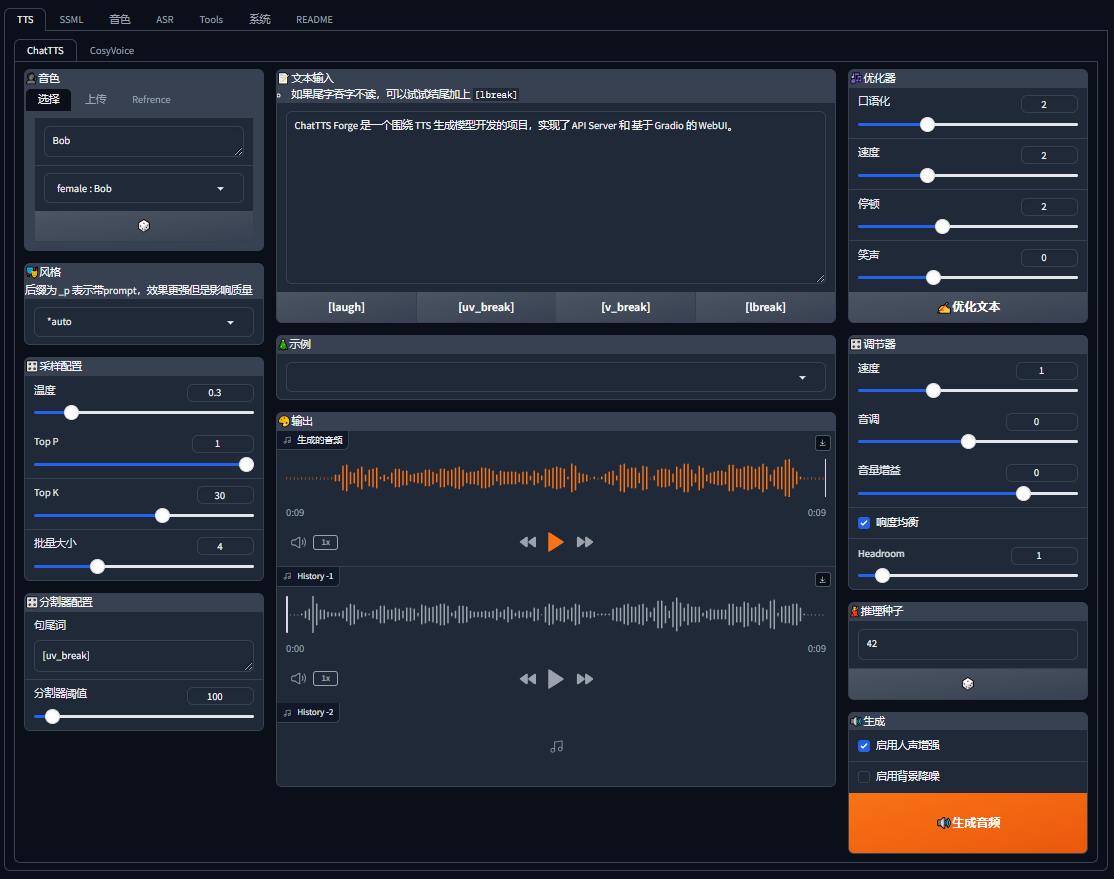
ChatTTS-Forge提供了各种API(应用程序编程接口),开发人员可以直接使用这些API轻松将文本转换为语音。此外,它还提供了易于使用的网页界面(WebUI),允许用户直接在网页上输入文本并生成语音,无需编程。
ChatTTS-Forge的主要特点:
TTS生成:支持多种TTS模型推理,包括ChatTTS、CosyVoice、FishSpeech、GPT-SoVITS等,用户可以自由选择和切换语音。
音调管理:内置多种音调,并且可以上传自定义音调。用户可以通过上传音频或文本来创建和使用自定义铃声。
风格控制:提供多种风格控制选项,包括调整语音速度、音调、音量,以及添加语音增强(Enhancer)以提高输出质量。
长文本处理:支持超长文本自动切分和推理,可以处理生成长文本音频内容。
SSML支持:使用类似XML的SSML语法进行高级TTS合成控制,适合更详细的语音生成场景。
ASR(自动语音识别) :集成Whisper模型,支持语音转文本功能。
ChatTTS-Forge的技术和方法:
API服务器:用Python编写的API服务器提供高效的TTS服务,支持多个并发请求和自定义配置。
WebUI :基于Gradio的用户界面,用户可以通过简单的操作界面体验TTS功能。
Docker 支持:提供 Docker 容器化部署选项,以简化本地和服务器上的部署过程。

ChatTTS-Forge WebUI 的特点:
TTS(文本到语音) :通过WebUI,用户可以使用各种不同的TTS模型输入文本并生成语音。
音调切换:支持多种预设音调切换,用户可以选择不同的声音来生成语音。
自定义语音上传:用户可以上传自己的语音文件,实时生成个性化语音。
风格控制:您可以调整语音的风格,包括语速、音高、音量等参数,以生成满足特定需求的语音。
长文本处理:支持处理很长的文本,自动将长文本分割成小段并按顺序生成语音,适合生成长音频内容。
批量处理:用户可以设置批量大小,以提高长文本的推理速度。
精炼器:这个工具 允许您微调文本以优化生成的语音,对于处理无限长度的文本特别有用。
语音增强:集成增强模型以提高生成语音的质量并使其听起来更自然。
生成历史:保存最近的3次生成结果,方便用户比较不同设置下的语音效果。
多模型支持:WebUI支持多种TTS模型,包括ChatTTS、CosyVoice、FishSpeech、GPT-SoVITS等,用户可以根据自己的需求选择合适的模型。
SSML支持:使用类似XML的SSML语法来控制语音合成过程,适合需要更复杂控制的场景。
播客工具:帮助用户从博客脚本创建长格式、多字符的音频内容。
字幕生成:从字幕文件创建 SSML 脚本以生成各种语音内容。
GitHub:https://github.com/lenML/ChatTTS-Forge
在线体验:https://huggingface.co/spaces/lenML/ChatTTS-Forge
数据评估
AI工具箱提供的ChatTTS-Forge都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由AI工具箱实际控制,在2024年10月6日 上午4:44收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,AI工具箱不承担任何责任。