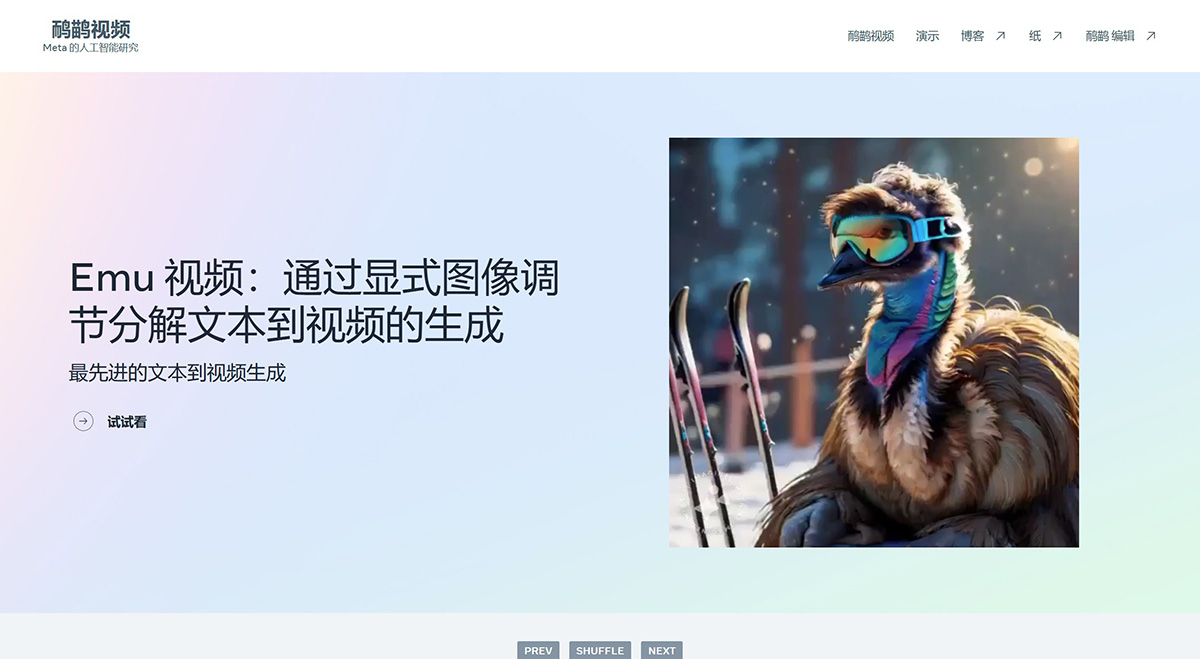
Emu Video,Meta 公司开发的文本到视频生成模型,一种基于扩散模型的简单文本到视频生成方法,Emu Video使用扩散模型根据文本提示创建视频,首先生成图像,然后根据文本和生成的图像创建视频。

Emu Video将生成过程分解为两个步骤:首先根据文本提示生成图像,然后根据提示和生成的图像生成视频。分解生成方式能够高效训练高质量的视频生成模型。相比以往的方法,Emu Video 的核心优势在于其高效性和生成内容的高分辨率。它能够生成分辨率为512×512、时长4秒、每秒16帧的视频片段。
Emu Video主要特征:
视频生成的统一架构:Emu Video 采用统一架构,支持各种视频生成任务,包括从纯文本提示、纯图像输入以及组合文本和图像输入生成视频。
两步分解方法:Emu Video 中的视频生成过程分为两个不同的步骤。首先,它根据文本提示生成图像。然后,它根据文本和生成的图像生成视频。
高分辨率输出:Emu Video 可以生成 512×512 像素的高分辨率视频,持续时间为 4 秒,帧速率为每秒 16 帧。
高效的训练过程:Emu Video 的训练过程被简化为两个阶段。首先,模型在较低分辨率 (256 像素) 和较短持续时间 (1 秒) 的视频上以每秒 8 帧的速度进行训练。接着它会以每秒 4 帧的速度转换为更高分辨率 (512px) 和更长持续时间(2 秒)的视频。
最先进的性能:与 Make-a-Video、Imagen-Video 等其他最先进的视频生成模型相比,Emu Video 在人类评估中表现出了卓越的性能。 96% 的受访者更喜欢它的质量,85% 的受访者更喜欢它忠实于文本提示。
用户提供的图像的动画:Emu Video可以根据文本提示对用户提供的图像进行动画处理,为希望将静态图像变为现实的用户添加另一层创造力和自定义功能。
Emu Video 应用:
内容创建:从简单的文本描述生成引人入胜的视频内容。
营销和广告:根据营销文案快速制作宣传视频。
教育和培训:根据教育材料制作教学视频。
娱乐:根据脚本或故事板制作动画故事或视觉内容。
Emu Video作为Meta开发的尖端文本转视频生成平台。使用分解方法来生成视频,能过文本提示创建图像,然后根据文本和图像生成视频。具有智能编辑功能,支持纯文本、纯图像和组合输入,以及以每秒 16 帧的速度生成高质量 512×512 视频的能力。
数据评估
AI工具箱提供的Emu Video都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由AI工具箱实际控制,在2024年10月6日 上午4:25收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,AI工具箱不承担任何责任。
相关导航