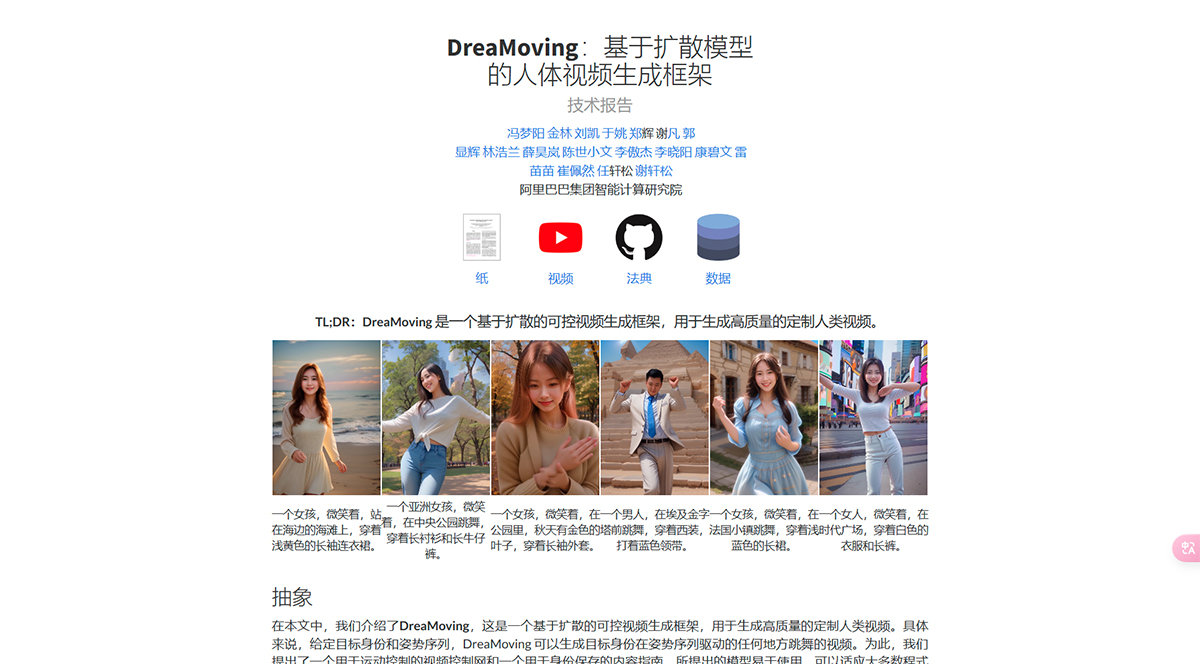
DreaMoving,一种基于扩散的可控视频生成框架,用于生成高质量的定制人类舞蹈视频。具体来说,给定目标身份和姿势序列,DreaMoving 可以生成目标身份在姿势序列驱动下在任何地方跳舞的视频。为此,我们提出了一个用于运动控制的视频控制网络和一个用于身份保留的内容指南。所提出的模型易于使用,并且可以适应大多数风格化的扩散模型以生成不同的结果。
DreaMoving项目地址:https://dreamoving.github.io/dreamoving
")
DreaMoving 概述:
Video ControlNet 是在每个 U-Net 块之后注入运动块的图像 ControlNet。Video ControlNet 将控制序列(姿态或深度)处理为额外的时间残差。Denoising U-Net 是一种衍生的 Stable-Diffusion U-Net,带有用于视频生成的运动块。内容导览器将输入文本提示和外观表达式(如人脸(布料是可选的))传输到内容嵌入中,以便交叉注意。
结果:
DreaMoving 可以生成高质量和高保真度的视频,给定指导序列和简单的内容描述,例如文本和参考图像作为输入。具体来说,DreaMoving 通过人脸参考图像、通过姿势序列进行精确运动操作以及由指定文本提示提示的全面视频外观控制来展示身份控制的熟练程度。
数据评估
关于DreaMoving特别声明
AI工具箱提供的DreaMoving都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由AI工具箱实际控制,在2024年10月6日 上午3:21收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,AI工具箱不承担任何责任。
AI工具箱致力于优质、实用的网络站点资源收集与分享!本文地址https://aitoolbox.cn/sites/26627.html转载请注明
相关导航











暂无评论...
AI工具箱赋能,引领产业升级新潮流。我们专注于AI绘画、AI游戏和AI视频等各大AI领域,提供最新最全的AI相关信息,包括AI工具软件、AI网址大全、AI热点资讯、AI学习图书等等。我们还提供免费AI软件教程,让您更轻松地掌握AI技术。我们致力于帮助AI爱好者实现自己的梦想,一起开创AI时代的未来!