模型方法--Stable Diffusion
最近大火的Stable Diffusion也开源了(20220823);
我也本地化测试了一下效果确实比Dall-E mini强太多了,对于我们这些玩不上Dall-E2的这个简直就是就是捡钱的感觉,当然后期跑起来,稍微不注意显存就炸了。
这里我写一下安装过程,具体分为两个安装流程;
流程1 -- Hubggingface的方式安装
使用Huggingface的模式进行直接安装。

注册
第一个工作需要注册账户,可以关联github;
注册后在个人目录下有一个token号;链接https://huggingface.co/settings/tokens,这个tokens号要在服务器登陆的过程中进行添加;
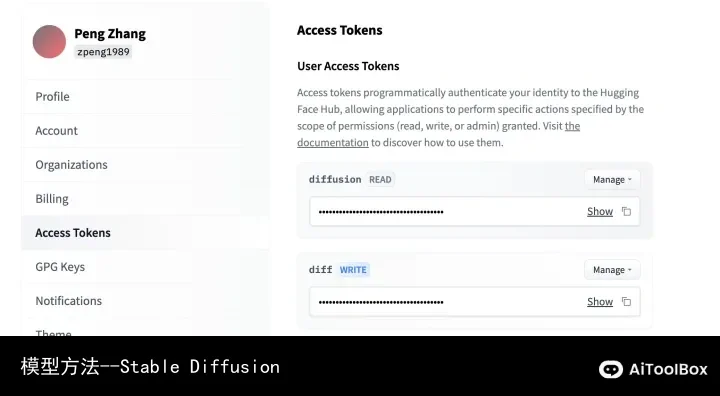
在服务器登陆要输入huggingface登陆:
登陆界面,输入token就可以分析;

之后才可以再安装;
相关包安装
安装配置的包命令:
安装过程时间会很长[最好修改镜像路径],一般不会出什么问题。
运行模式
然后直接运行下面的code就可以绘制图出来,第一次计算会下载模型权重,速度很长。国内网络很慢,建议选择其他网络方法,或者早起(早晨速度特别快)。
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id="CompVis/stable-diffusion-v1-1"
device = "cuda"
pipe=StableDiffusionPipeline.from_pretrained(model_id,use_auth_token=True)
pipe = pipe.to(device)
prompt="a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
可以调节其他参数,但这个流程具体我没有更多测试。
prompt = "fantasy magic fashion Asian girl portrait, glossy eyes, face, long hair, fantasy, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, renaissance, flowy, melting, round moons, rich clouds, very detailed, volumetric light, mist, fine art, textured oil over canvas, epic fantasy art, very colorful, ornate intricate scales, fractal gems, 8 k, hyper realistic, high contrast"
prompt = "All roads lead to Rome, 8 k, hyper realistic, high contrast, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration"
prompt = "Tomorrow is another day, 8 k, hyper realistic, high contrast, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration"
我测试的三组,效果如下:




流程2 -- 使用github进行分布部署
这种模式使用自己下载模型,运行时候使用参数会更好的结果。
通过下载GitHub下载原始代码,路径:

只用git clone 或者直接download的保存都可以,访问这个目录进行安装。
相关包安装
安装使用conda方式做的:GitHub - CompVis/stable-diffusion安装使用conda方式做的:
conda activate ldm
但我安装过程因为git clone之后报错,因为各种原因吧。
我是直接本地download下来,然后直接
具体包括的安装包有CLIP[openai/CLIP]和taming-transformers[CompVis/taming-transformers];这里说一下taming-transformers安装后依然找不到相关代码, 我直接把[taming]目录代码copy根目录下,这样直接import没有问题了。
一些相关包的安装:
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
这部分安装包括stable-diffusion的目录;
模型文件下载
访问网站[Hugging Face – The AI community building the future.]:
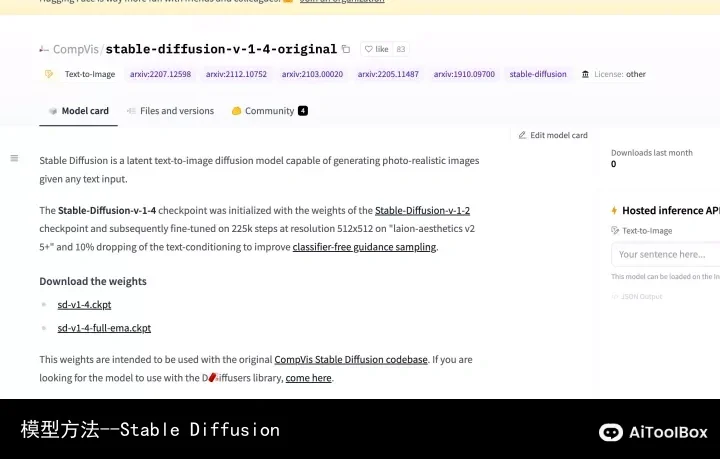
在Files and versions下载就可以,选择对应的sd-v1-4.ckpt下载,如图:
直接点后面的下载符号就可以下载,之后运行的时候只要链接到模型路径就可以计算。
运行模式1 - 文本转图像:
第一次运行还会安装、和配置很多模型,需要时间很多。
还是建议早起。
全部模型参数如下:
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
其中主要的参数(我使用的),
--prompt 关键词准备;
--plms 预测使用需要使用这个信息;
--W/--H 这里需要注意如果生成图太大,显存可能不足,建议一点一点试试;
--seed 种子数、相同prompt和seed会保证生成图像一致;
--ckpt 写模型的全路径,访问模型;
--outdir 图像生成路径,图绘按照ID顺着添加,目录下有一个文件夹路径会保留所有样本;
我测试的一个样例:
--plms
--outdir ./stable-diffusion-main/Workspace
--ckpt ./stable-diffusion-main/models/ldm/sd-v1-4.ckpt
--ddim_steps 100
--H 512
--W 512
--seed 8
输出结果:



运行模式2--图像+文本--图像
该部分就是通过一个随机图,给一些描述可以产出新的效果。我测试这部分。。。比较诡异;
如果有好的案例欢迎推荐给我,大家注意一下。
--init-img ./stable-diffusion-main/Workspace2/h3.jpg
--strength 0.8
--outdir ./stable-diffusion-main/Workspace
--ckpt ./stable-diffusion-main/models/ldm/sd-v1-4.ckpt
--ddim_steps 100
经过我测试还有很多人讨论的结果,输入图尽量保持长宽像素保持64的倍数,一般不会报错。
输入图像:
输出结果如下:
结果有点。。。不理解
但看小蓝鸟上还是很多不错的结果。
参考链接:
[1] CompVis/stable-diffusion-v1-1[CompVis/stable-diffusion-v1-1 · Hugging Face];
[2]CompVis/stable-diffusion[https://github.com/CompVis/stable-diffusion]